Odio l'Excel.
Bé, potser no tant... només l'odio quan l'he d'utilitzar en una ETL. Que si driver de 32 o 64 bits, que si problemes amb els tipus de dades, etc. però per molt que l'odii els usuaris no el deixaran de fer servir, així que ens haurem d'adaptar.
En els anteriors posts hem vist com utilitzar BIML per generar els dtsx per carregar les dades d'una BBDD SQL Server, ara veurem com fer-ho per fitxers Excel.
La part que més varia és la generació de metadata. A partir de tenir la metadata carregada la creació i esborrat de les taules és igual en tots els casos i la càrrega de dades és molt similar.
Anem a veure primer com queda l'esquema de BBDD de la metadata.

Veiem que com a filla de source tenim source_excel que serà el nostre fitxer excel, que tindrà un o diversos sheets.
Per extreure la metadata jugarem molt amb linked servers. Una altra alternativa és passar l'excel a CSV a través de powershell. En aquest vídeo del Miguel Egea ho explica molt bé (https://youtu.be/nJ5_xC--Y2I)
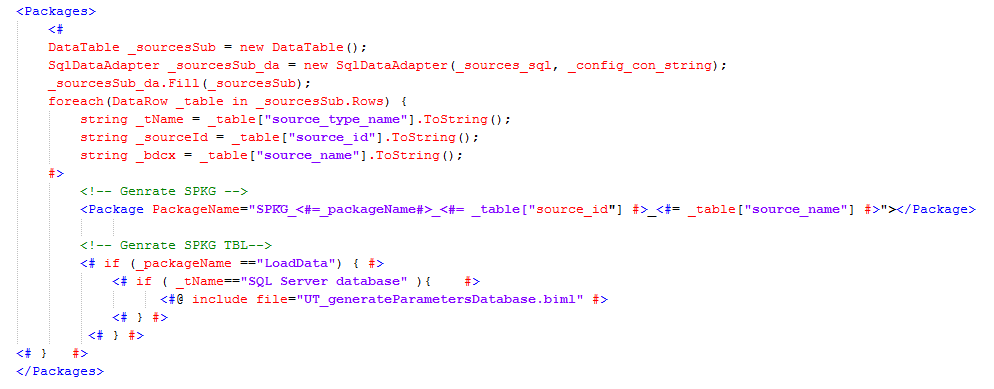
 Per a fonts d'origen excel podem generar automàticament el contingut de les taules source_detail i source_excel, source_column. L'atribut is_pk l'haurem d'informar manualment i el data_type podem agafar directament el que genera la metadata o bé modificar-lo a posteriori. Al fer sempre càrregues complertes no farà falta informar el camp incremental.
Per a fonts d'origen excel podem generar automàticament el contingut de les taules source_detail i source_excel, source_column. L'atribut is_pk l'haurem d'informar manualment i el data_type podem agafar directament el que genera la metadata o bé modificar-lo a posteriori. Al fer sempre càrregues complertes no farà falta informar el camp incremental.
El codi de generació de metadata per excel el teniu a https://github.com/jordiisidro/adeu-biml/blob/master/GenerateMetadataExcelSheet.biml
El primer que farem serà executar la funció: [sp_generateSheetsExcel] que omplirà les taules source_detail i souce_excel_table amb cadascun dels sheets dels fitxers excels definits a l'origen.

Posteriorment per a cada sheet crearem un linked server que ens crearà una taula amb el mateix format que l'excel a un esquema trash. Des d'allà farem com si en nostre origen fos directament SQL Server per extreure la metadata.
 A l'acabar de generar la metadata esborrarem la taula de l'esquema trash.
A l'acabar de generar la metadata esborrarem la taula de l'esquema trash.
Ara ja tenim la metadata generada, i seguint el mateix esquema que amb SQL Server podrem generar les taules a l'Staging Area.
Al proper post veurem com fer la generació de dtsx per a la càrrega de dades.
Com sempre podeu trobar tot el codi a: https://github.com/jordiisidro/adeu-biml/
Bé, potser no tant... només l'odio quan l'he d'utilitzar en una ETL. Que si driver de 32 o 64 bits, que si problemes amb els tipus de dades, etc. però per molt que l'odii els usuaris no el deixaran de fer servir, així que ens haurem d'adaptar.
En els anteriors posts hem vist com utilitzar BIML per generar els dtsx per carregar les dades d'una BBDD SQL Server, ara veurem com fer-ho per fitxers Excel.
La part que més varia és la generació de metadata. A partir de tenir la metadata carregada la creació i esborrat de les taules és igual en tots els casos i la càrrega de dades és molt similar.
Anem a veure primer com queda l'esquema de BBDD de la metadata.
Veiem que com a filla de source tenim source_excel que serà el nostre fitxer excel, que tindrà un o diversos sheets.
Per a que em funcionés tant amb fitxers xlsx com amb fitxers xls al servidor tenia instal·lat l'excel de 64 bits i Microsoft Access Database Engine 2010 Redistributablede 32 bits.
Per extreure la metadata jugarem molt amb linked servers. Una altra alternativa és passar l'excel a CSV a través de powershell. En aquest vídeo del Miguel Egea ho explica molt bé (https://youtu.be/nJ5_xC--Y2I)
El codi de generació de metadata per excel el teniu a https://github.com/jordiisidro/adeu-biml/blob/master/GenerateMetadataExcelSheet.biml
El primer que farem serà executar la funció: [sp_generateSheetsExcel] que omplirà les taules source_detail i souce_excel_table amb cadascun dels sheets dels fitxers excels definits a l'origen.
Posteriorment per a cada sheet crearem un linked server que ens crearà una taula amb el mateix format que l'excel a un esquema trash. Des d'allà farem com si en nostre origen fos directament SQL Server per extreure la metadata.
Ara ja tenim la metadata generada, i seguint el mateix esquema que amb SQL Server podrem generar les taules a l'Staging Area.
Al proper post veurem com fer la generació de dtsx per a la càrrega de dades.
Com sempre podeu trobar tot el codi a: https://github.com/jordiisidro/adeu-biml/