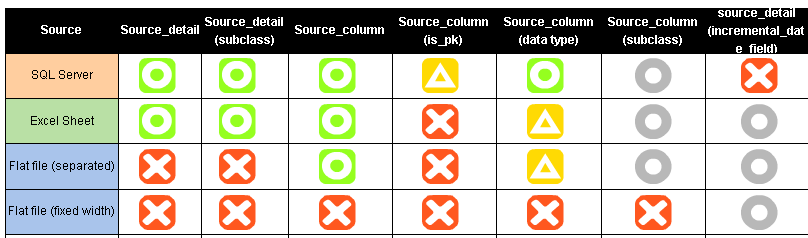
En els posts anteriors hem vist com generar amb BIML els dtsx que extreuen la metadata de BBDD SQL Server i que, a partir d'aquesta metadata, també podem generar els scripts de creació i esborrat de les taules de l'staging area i dels índexos. Avui toca mirar la part final, la generació dels dtsx que carreguin aquestes taules.
La càrrega de dades la farem amb la mateixa estructura que la resta de bimls. Teniu el codi a
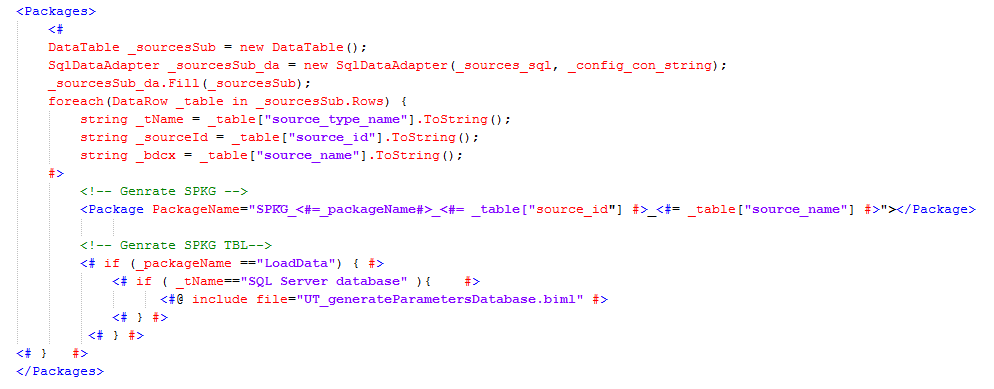
https://github.com/jordiisidro/adeu-biml/blob/master/004_LoadDataParent.biml
Per a la càrrega de dades des de SQL Server generarem un dtsx per a cada taula. El motiu es que si volem obrir després el codi del dtsx si hi ha moltes taules triga molt a fer les validacions. En el nostre cas, per contra, serà ràpid obrir els dtsx, però en podem arribar a tenir molts.
El fet de generar un dtsx per a cada taula i que estiguin les connexions parametritzades complica una mica la generació de paràmetres. En el fitxer UT_generateParameters.biml haurem d'afegir un bucle per a cadascun dels paquests (i per tant de les taules) que ens generi el nom del paquet. També haurem de generar un paquet per cada font de dades.
Si no volguéssim utilitzar paràmetres en el nostre codi aquesta part no faria falta.
Un cop tenim els paràmetres passem a generar els paquets pares per cada origen de dades diferent, que el que faran serà invocar als paquets fills (UT_generatePackages.biml) a través d'un
ExecutePackage. Cada origen de dades tindrà un paquet fill, i en el cas dels orígens SQL Server cada paquet fill tindrà més paquets fills amb cadascuna de les taules. Aquests paquets fills es generaran a UT_generateSubPackages.biml.
Des de UT_generateSubPackages.biml s'invoca a LoadDataDatabase.biml que el que fa és un bucle per cada taula i invoca als paquets fills (un per taula) també a través d'un
ExecutePackage.
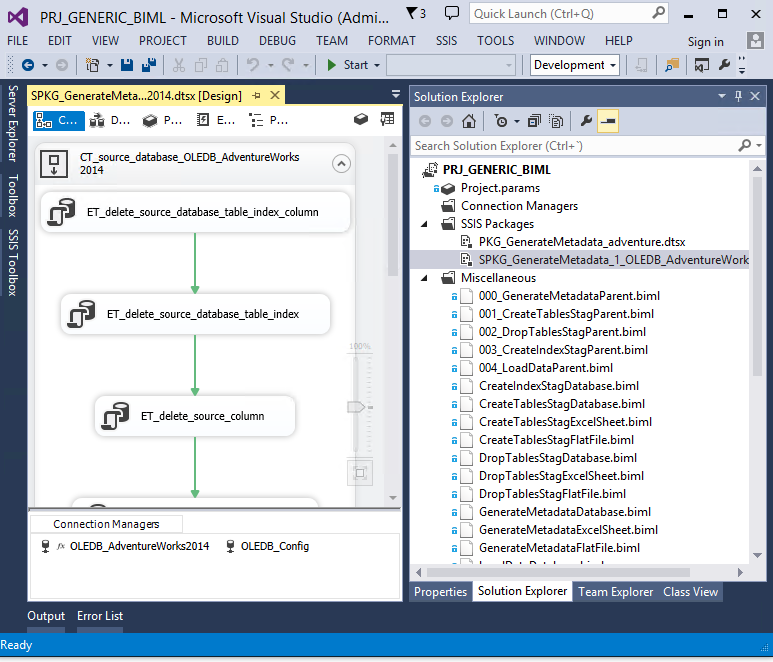
Finalment anem a implementar per fi la càrrega de dades, fins ara només hem generat paquets buits.
En el cas d'un origen SQL Server hem definit 2 tipus de càrrega: full i incremental. Per cadascuna d'elles hi haurà un biml diferent que s'invocarà segons el que s'hagi definit a la metadata.
Per a la càrrega full farem un truncate de la taula.
Seguit d'un dataflow on farem un select des de l'orígen (evitarem el select * i generarem el select <columnes>* ja que tenim la metadata) i ho bolcarem a l'staging area. També guardarem en una variable el nombre de files, que ens anirà molt bé a l'hora de debugar.
I finalment guardarem el nombre de files a una taula de log.
I ja tenim implementada la càrrega full!
Per a la càrrega incremental haurem de definir 2 variables de data per utilitzar-les de filtre i les alimentarem a través d'un ExecuteTask.
També farem el truncate table de l'staging area i un dataflow. En el dataflow utilitzarem les variables de data amb el camp que hem definit a la metadata com a data de modificació.
I també guardarem el nombre de files carregades.
I ja tenim també implementada la càrrega incremental!
Si en el nostre entorn necessitéssim altres tipus de càrrega només hauríem d'implementar el biml corresponent, la resta d'estructura es reutilitzaria.
En aquest punt ja podem generar el codi per omplir l'staging area dels nostres origens SQL Server.
En els propers posts explicarem el mateix procés per altres orígens com fitxers Excel i fitxers plans.
Com sempre tot el codi el trobareu al github: https://github.com/jordiisidro/adeu-biml/

 La ponència que presentaré serà: "Extracción automàtica de datos mediante BIML" on expicaré com generar la metadata i els dtsx mitjançant BIML per a extreure dades d'orígens com SQL Server, Excels, fitxers plans. Bàsicament el que he estat escrivint en els posts anteriors.
La ponència que presentaré serà: "Extracción automàtica de datos mediante BIML" on expicaré com generar la metadata i els dtsx mitjançant BIML per a extreure dades d'orígens com SQL Server, Excels, fitxers plans. Bàsicament el que he estat escrivint en els posts anteriors.